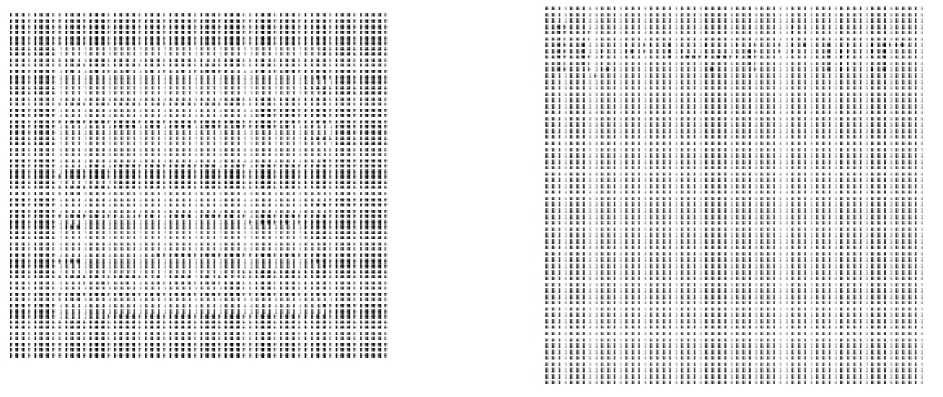
Figure 1. Examples of document image representation: Scientific Article (left) and Magazine (right).
Our interest in image features reflects the
recognition that documents of certain genres have more
white space on the first page (e.g. title page of the book),
are ruled by formatting conventions (e.g. first slide for a
conference presentation), and are made visually elaborate
to attract readership (e.g. the reversal of black and white
on a magazine cover). Another benefit of examining
documents using image processing methods is that the
process does not depend on extracting text, can be
language independent, and supports document analysis
even when the content of the document is only accessible
as an image. Examples of the image representation are
given in Figure 1.
The features in style are intended to capture
frequency of words popular to all genres as well as words
which are only prolific within some genres. A typical
example of the weight of this feature is illustrated in the
fact that forms or slides are likely to contain a fewer
number of definite or indefinite articles than flowing text.
Sample average frequencies of words commonly found in
three of the genres discussed in the current study are
presented in Table 1 (the average is taken over ten
documents). In the reported experiment we have taken
words which were found in 75% of the files in each genre.
We have also tried with a few other percentages but found
this to show the best results. To compile the common
words, we also tried a focused method of compiling words
from the six genres under consideration only, and even
words from a range of genres which exclude the genres of
interest. The combined list was adopted in the end
because higher accuracies were consistently observed in
all three style-based classifiers when using this list in
comparison to the other two lists.
Table 1. Average frequency of words per document
across three genres.
|
Genre Word |
Business Report |
Thesis |
Minutes |
|
have |
47 |
109 |
0 |
|
with |
71 |
210 |
13 |
|
do |
11 |
0 |
0 |
|
case |
0 |
10 |
0 |
|
meeting |
0 |
0 |
8 |
|
information |
12 |
0 |
0 |
5. Experiments
5.1. Method
Eight classifiers (image NB, image SVM, image
RF, style NB, style NB, style SVM, style RF, Rainbow
NB, Rainbow SVM) have been tested on Dataset I and II
for their performance in recognising six genre classes
including Academic Monograph, Book of Fiction,
Business Report, Minutes, Periodicals, and Thesis. The
performance is examined using 10-fold cross validation
results.
The performances of the eight classifiers are
first evaluated to identify, for each feature type, the
statistical methods that generate the best overall
performances on Dataset I and II (Section 6.1). Then, on
each dataset, the best classifiers, one for each feature type,
More intriguing information
1. The name is absent2. Education as a Moral Concept
3. ENVIRONMENTAL POLICY: THE LEGISLATIVE AND REGULATORY AGENDA
4. HACCP AND MEAT AND POULTRY INSPECTION
5. The name is absent
6. The name is absent
7. The name is absent
8. The Dynamic Cost of the Draft
9. The InnoRegio-program: a new way to promote regional innovation networks - empirical results of the complementary research -
10. Hemmnisse für die Vernetzungen von Wissenschaft und Wirtschaft abbauen