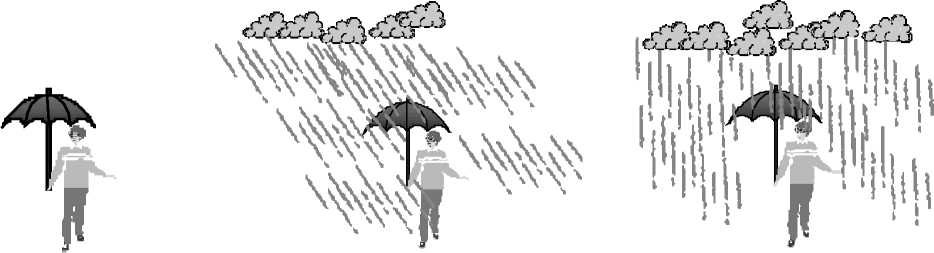
Figure 1: Examples of experimental conditions in the second experiment of Coventry et al. [5]. The three scenes differ in the level of
variable Function. In the control condition (left) there is not rain, in the non-functional condition (center) the umbrella does not protect
the man from the rain, and in the functional condition (right) the umbrella is fulfilling its function of protection the man from the rain.
can be rotated at 90, 45, and 0 degrees) Function
fulfillment of protection from the rain (3 levels: yes, no,
control), Appropriateness of object for protection
function, e.g. umbrella or suitcase (2 levels: yes, no) and
Object type (4 levels). This results in 72 experimental
scenes/conditions. An example of three scenes is presented
in Figure 1. The scenes differ in the level of the variable
Function.
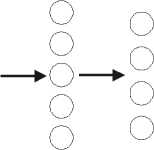
Three network architectures are used. They only differ in
the number of input units and the way input scenes are
encoded. The five hidden units and the four output units are
the same in all networks (Figure 2).
Orientation:
yes U
Functionfulfill: no U
control O
OVER
UNDER
ABOVE
BELOW
Object Properties O
(Iocalist or feature) O
Figure 2: Neural network architecture
Network A: Localist experiment encoding
In this network, the number of input units exactly reflects
the number and levels of the four experimental variables.
This architecture has a total of 12 localist input units. We
use the term localist to indicate that for each variable only
one unit is active.
Three input units are used to encode the three levels of
Orientation of the protecting object. Three localist units
are used for the three levels of the Function independent
variable. Two units encode the levels of Appropriateness,
and four units the types of Object.
Network B: Localist Object Encoding
This network does not have an explicit representation of the
object appropriateness, because eight localist units are used
to represent all objects. There are also three localist units
for Orientation and three for Function. This architecture
has a total of 14 input units.
Network C: Feature-based Object Encoding
In this network the objects are encoded according to their
geometrical and functional features. Each object is
represented using eight feature-based units. Three units
encode the dimension of the object in the three dimensions
(x, y, z) and three encode the major shape components
(hemispherical, conical, cuboid). Two units refer to the
lexicalized function of the object (i.e. Appropriateness).
For example, the object umbrella is encoded as x=1, y=1,
z=.67, hemispherical=1, conical=0, cuboid=0,
appropriate=1, inappropriate=0.
There are three localist units for Orientation and three for
Function. This architecture has a total of 14 input units.
Training
A standard error backpropagation algorithm was used, with
a learning rate of .01, momentum of .9 and 10000 epochs.
Of the total of 72 scenes, 71 were used for each training
epoch, and 1 for the generalization test. The training of each
network type A/B/C was replicated ten times, by varying
the initial random weights and the stimulus randomly taken
out for the generalization test.
The subjects’ mean ratings for the use of the four
prepositions were normalized in the range 0-1 and were
used as teaching input for the backpropagation training.
2.2 Virtual Reality Environment
The VR module consists of an interface for the
manipulation of 3D objects in the scene. For example, in
the umbrella scene there are three objects that the user can
manipulate: the man, the protecting object (e.g. umbrella or
More intriguing information
1. If our brains were simple, we would be too simple to understand them.2. The Effects of Reforming the Chinese Dual-Track Price System
3. Alzheimer’s Disease and Herpes Simplex Encephalitis
4. The name is absent
5. Analyzing the Agricultural Trade Impacts of the Canada-Chile Free Trade Agreement
6. Should Local Public Employment Services be Merged with the Local Social Benefit Administrations?
7. Importing Feminist Criticism
8. Using Surveys Effectively: What are Impact Surveys?
9. Dual Track Reforms: With and Without Losers
10. The Impact of Cognitive versus Affective Aspects on Consumer Usage of Financial Service Delivery Channels