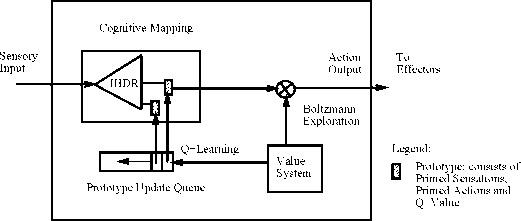
Figure 1: System architecture of SAIL experiments.
A major problem with a reward is that it is typ-
ically delayed. The idea of value backpropagation
used in Q-Iearning is applied here. A challenge of
online incremental development is that global itera-
tion is not allowed for speed considerations. We use
a first-come first-out queue, called prototype update
queue, which stores the addresses of formerly visited
primitive prototypes. This queue keeps a history of
prototype through which reward is backpropagated
recursively but only locally, avoiding updating all
the states (which is impossible for real-time devel-
opment).
3. The value system
Iated as a mapping M: SxX —> X' × A × Q, where
S is the state (context) space, X the current sensory-
space, X' the space of primed sensation, Q the space
of value and A is the action space. In every time
step, M accepts the current sensory input x(t) and
combines it with the current state s(t) to generate
the primed sensation X'(t) and the corresponding
action output a{t + 1). The cognitive mapping is re-
alized by the Incremental Hierarchical Discriminant
Regression (IHDR) tree (Hwang and Weng, 1999)
(Weng and Hwang, 2000), which derives the most
discriminating features and uses a tree structure to
find the best matching in a fast logarithmic time.
Compared with other methods, such as artificial neu-
ral network, linear discriminant analysis, and prin-
cipal component analysis, IHDR has advantages of
dealing with high-dimensional input, deriving dis-
criminant features autonomously, learning incremen-
tally, allowing one-instance learning, and low time
complexity.
The current context is represented by context vec-
tor c(t) ∈ S × X. Given c(t), the IHDR tree finds
the best match prototype c' among a large number
of candidates. Each prototype c' is associated with
a list of primed contexts: ⅛1,P2, ∙-,Pk}∙ lɑ each
primed context, pi consists of primed sensation xp,
primed action ap and corresponding Q value. The
primed sensation is what the robot predicts to sense
after taking the corresponding primed action. The
Q value is the expected value of the corresponding
action. Given the list of primed contexts, it is the
value system that determines which primed action
should be taken based on its Q-value. Reinforce-
ment learning is integrated into the value system.
After taking one action, the robot enters a new state.
The value system calculates the novelty by comput-
ing the difference between the current sensation in
the new state and the primed sensation in the last
state. Then the novelty is combined with immediate
reward to update the Q value of the related actions.
More detail about the value system is discussed in
the next section.
The value system of a developmental robot sig-
nals the occurrence of salient sensory inputs,
modulates the mapping from sensory inputs
to action outputs, and evaluates candidate ac-
tions (Sporns, 2000) (Montague et al., 1996). The
value system of the central nervous system of a robot
at its “birth” time is called innate value system. It
further develops continuously throughout its “life”
experience. The value system of a human adult is
very complex. It is affected by a wide array of social
and environmental factors. The work reported here
deals with only some basic low level mechanisms of
the value system, namely, a novelty and reward based
integration scheme.
3.1 Spatial and temporal bias
The innate value system of a developmental robot
is designed by the programmer. It includes the fol-
lowing two aspects: innate spatial bias and innate
temporal bias. The term “spatial” here means dif-
ferent sensory elements with different signal prefer-
ences are located at different locations of the robot
body. The term “temporal” means that the spatial
bias changes with time. For example, a pain signal
from a pain sensor is assigned a negative value and a
signal from a sweet taste is assigned a positive value.
This is an innate spatial bias. If a pain sensor con-
tinuously sends signal to the brain for a long time
period, a newborn does not feel the pain as strong
as it is sensed for the first time. This is a temporal
bias (Domjan, 1998).
3.2 Novelty and immediate reward
Novelty plays a very important role in both non-
associative learning and classical conditioning. It is
a part of the value measured by the value system.
As shown in Fig. 1, every prototype retrieved
from the IHDR tree consists of 3 lists: primed
sensations X = (xp1,xp2, ...,xpn), primed actions
A = (apι,ap2, ...,apn) and corresponding Q values
Q = (¾1,¾2, ∙∙∙,¾n)∙ The innate value system eval-
More intriguing information
1. A NEW PERSPECTIVE ON UNDERINVESTMENT IN AGRICULTURAL R&D2. The name is absent
3. Transport system as an element of sustainable economic growth in the tourist region
4. Better policy analysis with better data. Constructing a Social Accounting Matrix from the European System of National Accounts.
5. The name is absent
6. Sex-gender-sexuality: how sex, gender, and sexuality constellations are constituted in secondary schools
7. References
8. Gender stereotyping and wage discrimination among Italian graduates
9. The name is absent
10. Macro-regional evaluation of the Structural Funds using the HERMIN modelling framework