2. Revisiting Phylomemetic Tree
The steps to build the general phylomemetic tree should be conjectured to the distance matrix
between artifacts. The distance of the artifacts will eventually give opportunity to visualize the
clustering of the artifacts based on the observed features as the heart of the phylomemetic analysis.
We can point at least three steps should be taken in the methodology, i.e.:
First, we should have the tables of the memeplexes as discussed in Situngkir (2004). There could
possibly some ways to do this based upon the kinds of artifacts we would like to approach. One
simplest way could be made is by pointing interrogative (yes/no) questions about the existence of
some features and characteristics of the artifacts (Heylighen, 1993). Furthermore, more rigorous
steps that can be conducted is by using some methodology by acquisition of some statistical
methodology about the features. Extraction of detailed and quantitative information from the
artifacts by considering certain features can also been taken. The quantitative information thus may
be categorized into several groups of values from which we can have the bases of the memeplex. An
exemplification can be seen as it has been shown in Situngkir (2007) on the clustering tree of some
Northern Sumatera languages. The quantitative variables can be transformed into several qualities
e.g. the fuzzy modeling for instance.
x∈ R ——→{m = f (x)}∈ N (1)
where N is finite. But it is also worth noting that if one has long sequence of memeplex, the
memeplex can also be stated as series of real numbers,
m= ∪ xi
i
(2)
The latest sort of modeling would sometimes be able to yield the strong and strict phylomemetic
tree but not always. It all depends on the observed artifacts.
Second, from the table of the memeplex we can now construct the the distance matrix among the
cultural objects. In this step, we can do comparation between two memeplexes that directly yields
the Hamming distance between two artifacts or do the alignment algorithm as it has been discussed
in Khanafiah & Situngkir (2007). For memeplex with constituted by binary strings, the hamming
distance can be measured as the numbers of different bits,
3_g =| mi XOR m 2 II
(3)
There would also possibilities that one do not do the categorization as depicted in eq. 1 - while
memeplexes are obtained from the series of (quantitative-) information extracting algorithms - the
correlation coefficient ( ρ(m1,m2)) can be used to compare memeplexes.
ρ(m1,m2)=
m1m2 - m1 m2
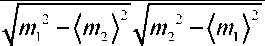
(4)
The greaterρ(m1,m2) the more two memeplexes are correlated and the less it is the less correlated
the two are, while the closer it is to zero, the more the two uncorrelated. Even though some works
regarding to the more rigorous terms on deciding between the two are necessary for future
conjectures, we could see that the two would have given us explanation of the representation of
differences among memeplexes, and cultural artifacts in general. We would like to cite Mantegna &
More intriguing information
1. Party Groups and Policy Positions in the European Parliament2. Impact of Ethanol Production on U.S. and Regional Gasoline Prices and On the Profitability of U.S. Oil Refinery Industry
3. Innovation Trajectories in Honduras’ Coffee Value Chain. Public and Private Influence on the Use of New Knowledge and Technology among Coffee Growers
4. The name is absent
5. L'organisation en réseau comme forme « indéterminée »
6. Categorial Grammar and Discourse
7. Ultrametric Distance in Syntax
8. Optimal Vehicle Size, Haulage Length, and the Structure of Transport Costs
9. Sector Switching: An Unexplored Dimension of Firm Dynamics in Developing Countries
10. The name is absent