βEtVt+1
αt+1et+1
V' j j
x∈^-∣αt αt+1et+1
Rt+1 -
(ei+1)1+ηi
ι+ηi
- -σi
- xt+1
et+1(∑j∈τ∖{i} αt+1et+1)
(Pj∈ι αj+1ej+1)2
γt - βiEtγl+ι (1 - δ (st+1))
αt+ι = (1 - δi (st) )αt + ztxt
δ (st) = δ + a (s⅛ -
ι)+4⅛-1
We assume ad hoc the following rule for adjusting the subjective valuation:
vi+ι = ■
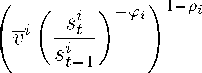
where ρt ∈ [0,1] is a smoothin g parameter, φt ≥ 0 represents the sensitivity of the rule to the results
from the recent past and
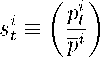
is our “success index”8, being vi > 0 the long-run value for the value scale parameter and pt the
optimal share of the good appropriated by agent i ∈ I in the deterministic steady state.
We are assuming that greater success reduces the value scale parameter for the next period. Note
that in the deterministic steady state we have st = 1 and vt = vt+1 = vt-
The first one of the optimality conditions implicitly defines a “reaction function” of the form
et = et ɑ) '' ,∑, Rt}
Because the utility function is concave, the cost function is convex and the conflict technology
is concave, then we know that the “reaction functions” are maximizers. By solving the system of
“reaction functions” we obtain the effort levels of equilibrium.
For the case in which all the agents are totally equal to each other, formally ∀i ∈ I, σt = σ,
8This success index si simply is the difference between what each player really won and what should have won in a
hypothetical steady state.
14
More intriguing information
1. The name is absent2. Improving behaviour classification consistency: a technique from biological taxonomy
3. Testing Hypotheses in an I(2) Model with Applications to the Persistent Long Swings in the Dmk/$ Rate
4. NEW DEVELOPMENTS IN FARM PRICE AND INCOME POLICY PROGRAMS: PART I. SITUATION AND PROBLEM
5. IMMIGRATION POLICY AND THE AGRICULTURAL LABOR MARKET: THE EFFECT ON JOB DURATION
6. The name is absent
7. Creating a 2000 IES-LFS Database in Stata
8. INSTITUTIONS AND PRICE TRANSMISSION IN THE VIETNAMESE HOG MARKET
9. The voluntary welfare associations in Germany: An overview
10. Searching Threshold Inflation for India