Simplifying, in the special case that v = O, equations (11) and (26) collapse to
^t + — (yt — yt_i ) = o, (27)
к
πt + —yt = O, (28)
к
respectively. It follows that the state is described by ut for the discretionary policy, by ut
and λπt for the optimal commitment policy, and by ut and yt_i for the timeless perspective
policy. As I now illustrate numerically,8 the performances associated with each of these
policies depends importantly on how these differences among the state variables is treated.
A: Conditional Loss
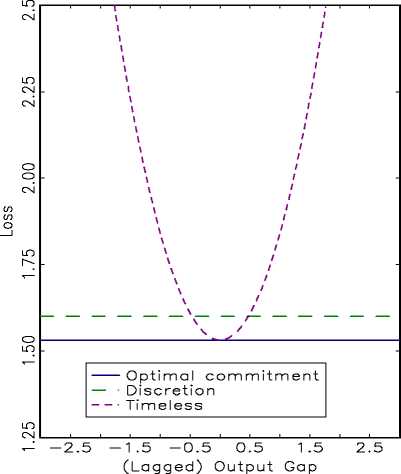
B: U n co nd ition a I Loss
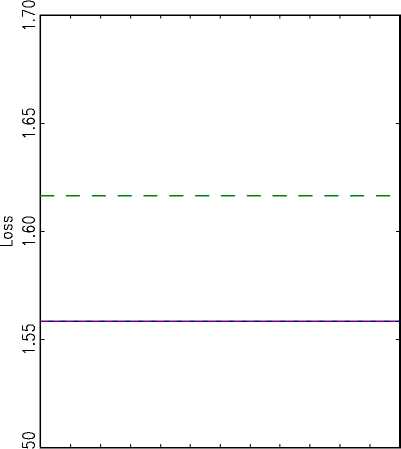
—’ — 2.5 -1.5 -0.5 0.5 1.5 2.5
(Lagged) Output Gap
Fig. 1
One way to measure the performance of each policy is to simply evaluate equation (14)
conditional on the relevant initial states. For the optimal commitment policy and the dis-
cretionary policy, it is straightforward to evaluate equation (14), since both policies assume
a given known value for uŋ and since for the optimal commitment policy it is known that
Λπo = O. It is slightly more complicated for the timeless perspective policy, since that policy
requires an initial value for y_i, the lagged output gap.
Consider Figure 1A, which displays performances for uo = O and for an array of different
initial values for the lagged output gap. By construction, the optimal commitment policy
8I parameterize the model according to к = 0.025, ρu = 0.20, β = 0.99, σeu = 1, and μ = 0.50.
11
More intriguing information
1. Education and Development: The Issues and the Evidence2. The name is absent
3. ISSUES IN NONMARKET VALUATION AND POLICY APPLICATION: A RETROSPECTIVE GLANCE
4. The name is absent
5. The name is absent
6. The Importance of Global Shocks for National Policymakers: Rising Challenges for Central Banks
7. The name is absent
8. The name is absent
9. Computational Batik Motif Generation Innovation of Traditi onal Heritage by Fracta l Computation
10. Public-Private Partnerships in Urban Development in the United States