Layer
No.
Inter-neuron distance
Size of the
receptive field
H
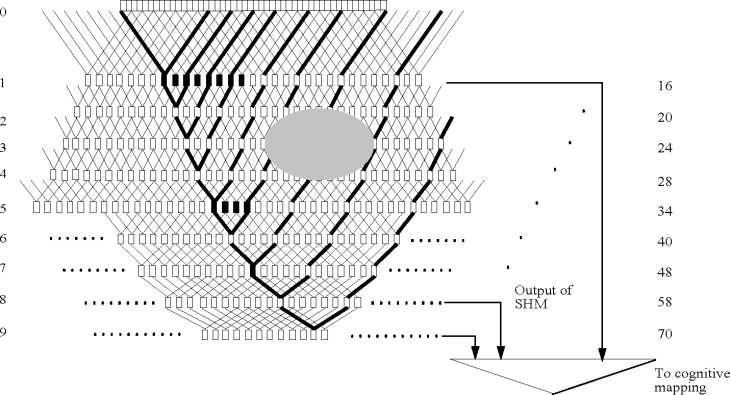
Figure 6: The architecture of SHM. Each square denotes a neuron. Layer 0 is the input image. The neurons marked
as black in layer 1 belong to the same eigen-group. Bold lines that are derived from a single neuron and expanded to
the original image mark the receptive field of that neuron. The size of the receptive field in a particular layer is 20%
larger than its previous layer in this diagram, which is shown at the right. The size of the receptive field is rounded to
the nearest integer. SHM allows not only a bottom up response computation, but also a top down attention selection.
The oval indicates the lines selected by attention selector.
any range sensors. Fig. 7 shows some images that
the robot saw during the navigation.
4.4 Grounded speech learning
Similar to learning vision-guided navigation, the
SAIL robot can learn to follow voice com-
mand through physical interaction with a human
trainer (Zhang and Weng, 2001b). In the early su-
pervised learning stage, a trainer spoke a command
to the robot and then executed a desired action by
pressing a pressure sensor or a touch sensor that was
linked to the corresponding effector. At later stages,
when the robot can explore more or less on its own,
the human teacher uses reinforcement learning by
pressing its “good” or “bad” button to encourage and
discourage certain actions. Typically, after about
15-30-minute interactions with a particular human
trainer, the SAIL robot could follow commands with
about 90% correct rate. Table 1 shows the voice
commands learned by the SAIL robot and its perfor-
mance. Fig. 8 shows the graphic user interface for
humans to monitor the progress of online grounded
speech learning.
4.5 Communicative learning
Recently, we have successfully implemented the new
communicative learning mode on the SAIL robot.
First, in the language acquisition stage, we taught
SAIL simple verbal commands, such as “go ahead,”
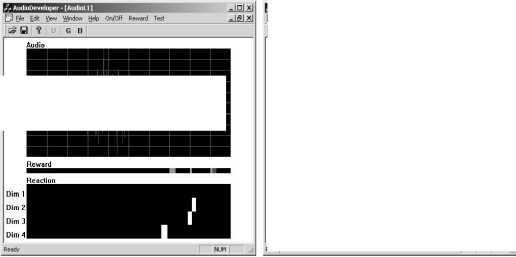
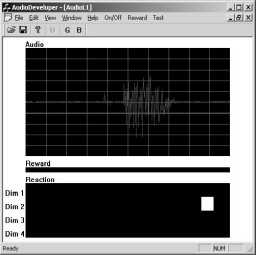
(a)
(b)
Figure 8: The GUI of AudioDeveloper: (a)During online
learning; (b)After online learning.
MMMUI Idll У Il MMMMM
MMMIlilIiIlMMMMM
MMMIIllinHMMMMM
■ IMM≡IIW≡MBBMI BI - -∙ I
“turn left,” “turn right,” “stop,” “look ahead,” “look
left,” “look right,” etc by speaking to it online while
guiding the robot to perform the corresponding ac-
tion. In the next stage, teaching using language, we
taught the SAIL robot what to do in the correspond-
ing context through verbal commands. For exam-
ple, when we wanted the robot to turn left (a fixed
amount of heading increment), we told it to “turn
left.” When we wanted it to look left (also a fixed
amount of increment), we told it to “look left.” This
way, we did not need to physically touch the robot
during training and used instead much more sophis-
ticated verbal commands. This made training more
efficient and more precise. Fig. 9 shows the SAIL
robot navigating in real-time along the corridors of
More intriguing information
1. Endogenous Determination of FDI Growth and Economic Growth:The OECD Case2. Willingness-to-Pay for Energy Conservation and Free-Ridership on Subsidization – Evidence from Germany
3. Backpropagation Artificial Neural Network To Detect Hyperthermic Seizures In Rats
4. The name is absent
5. Return Predictability and Stock Market Crashes in a Simple Rational Expectations Model
6. The name is absent
7. Volunteering and the Strategic Value of Ignorance
8. Road pricing and (re)location decisions households
9. The name is absent
10. Markets for Influence