process and make the assumption that counting ob-
jects has to grow on two distinct but parallel abili-
ties: the ability to sequentially focus the interesting
objects in the visual scene and the ability to learn
the counting sequence “one two three four...”. In the
two next sections, we will briefly present biologically-
inspired computational models for these two abilities
and then show how then can be coupled to produce
cardinal comparisons.
3. A Spatial Attention-Switching
Mechanism
There is no need in a robotic task to analyze ev-
ery pixel in the image grabbed by the camera of
the robot. Important targets or clues are salient
locations on the image, with respect to different
features (colour, orientation, luminosity, movement,
etc.) and at different scales. Analysing a visual scene
is then sequentially focusing these salient locations
until the correct target is found. Furthermore, the
features involved in the computation of salience can
be biased by task requirements.
In (Vitay et al., 2005), we presented a compu-
tational model of dynamical attention-switching
based on the Continuum Neural Field Theory
(Amari, 1977, Taylor, 1999), a framework of dy-
namical lateral interactions within a neural map.
Each neuron is described by a dynamical equation
which asynchronously takes into account the activ-
ity of the neighbouring neurons via a “mexican-
hat” lateral-weight function. We pinpointed
some interesting properties of that framework in
(Rougier and Vitay, 2005) like denoising and spatio-
temporal stability. Combining different neural maps
with the same dynamical equation while playing with
afferent and lateral weights, we were then able to
make emerge a sequential behaviour from this com-
pletely distributed substrate.
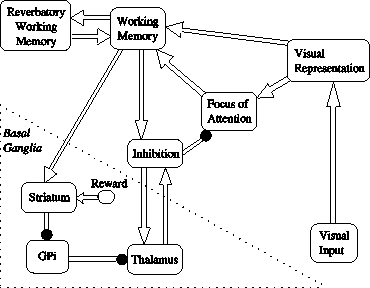
Figure 1: Attention Switching Architecture: empty
arrows represent excitatory connections, round ar-
rows represent inhibitory ones. For details, see
(Vitay et al., 2005).
Figure 1 shows the architecture of the proposed
system, but its description would need too much neu-
rophysiological jargon for the audience of this work-
shop. We just need to say that it is composed of four
sub-structures:
- a visual representation system fed by the saliency
image that can filters out noise and allows only one
salient location to be represented in the focus of
attention map.
- a working memory system that enables to dy-
namically remember previously focused objects.
- an inhibition mechanism which can move the fo-
cus of attention to a new salient location (with the
information given by the working memory).
- a basal-ganglia-like channel which can control the
time of the switch of attention. The key signal is a
phasic burst of dopaminergic activity in the reward
unit.
As a consequence of this distributed and dynami-
cal architecture, the serial behaviour that emerges is
the sequential focusing of the different salient points
on the image, without ever focusing twice the same
object. Moreover, the time of the switch is controlled
by the dopaminergic burst in the reward unit. We
will use that property for the counting task presented
later. This model has been successfully implemented
on a P eopleBotR robot, whose task was to succes-
sively focus with its mobile camera a given number
of green lemons. A nice feature of this model is that
it can work either in the covert mode of attention
(without eye movement) or in the overt mode (with
eye movements, because of the dynamic updating of
the working memory with visual information).
4. A Sequence Learning Mechanism
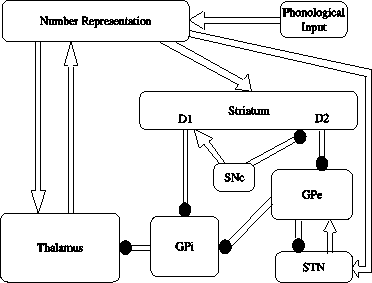
Figure 2: Ordinality Learning Architecture: empty ar-
rows represent excitatory connections, round arrows rep-
resent inhibitory ones.
This system relies on the basal ganglia (BG) ar-
chitecture, as summarized by (Hikosaka et al., 2000)
and is directly inspired by the model made by
(Berns and Sejnowski, 1998). BG are known to be
126
More intriguing information
1. The name is absent2. Bargaining Power and Equilibrium Consumption
3. The name is absent
4. Special and Differential Treatment in the WTO Agricultural Negotiations
5. Computational Batik Motif Generation Innovation of Traditi onal Heritage by Fracta l Computation
6. News Not Noise: Socially Aware Information Filtering
7. The name is absent
8. Evolutionary Clustering in Indonesian Ethnic Textile Motifs
9. NEW DEVELOPMENTS IN FARM PRICE AND INCOME POLICY PROGRAMS: PART I. SITUATION AND PROBLEM
10. 09-01 "Resources, Rules and International Political Economy: The Politics of Development in the WTO"