IJCSI International Journal of Computer Science Issues, Vol. 4, No 1, 2009
18
approach ([18], [19]), due to the difficulty in
understanding the decision making process of the NN,
which can lead to not knowing if testing has succeeded.
AIRS in [4] used the knowledge acquired during the
training of a NN to modify the user’s query, making it
possible for the adapted query to retrieve more documents
than the original query. However, this process would
sometimes give more importance to the knowledge
‘learnt’, thus change the original query until it lost its
initial keywords.
Researchers in [6] and [14] proposed a term frequency
method to select the feature vectors for the classification
of documents using NNs. A much later research ([3]) used
NNs together with an SVM for better classification
performance. The content of each web page was analysed
together with the content of its neighbouring pages. The
resulting feature scores were also used by the SVM.
Using two powerful techniques may radically improve
classification; however, this research did not combine the
techniques to create a more sophisticated one. They simply
used them one after the other on the same data set, which
meant that the system took much longer to come up with
results.
3. NB Classifier
Our system involves three main stages (Fig. 1). In stage-1,
a CRAWLER was developed to find and retrieve web
pages in a breadth-first search manner, carefully checking
each link for format accuracies, duplication and against an
automatically updatable rejection list.
In stage-2, a TRAINER was developed to analyse a list of
relevant (training pages) and irrelevant links and compute
probabilities about the feature-category pairs found. After
each training session, features become more strongly
associated with the different categories.
The training results were then used by the NB Classifier
developed in stage-3, which takes into account the
‘knowledge’ accumulated during training and uses this to
make intelligent decisions when classifying new, unseen-
before web pages. The second and third stages have a very
important sub-stage in common, the INDEXER. This is
responsible for identifying and extracting all suitable
features from each web page. The INDEXER also applies
rules to reject HTML formatting and features that are
ineffective in distinguishing web pages from one-another.
This is achieved through sophisticated regular expressions
and functions which clean, tokenise and stem the content
of each page prior to the classification process. Features
that are believed to be too common or too insignificant in
distinguishing web pages from one another, otherwise
known as stopwords, are also removed. Care is taken,
however, to preserve the information extracted from
certain Web structures such as the page TITLE, the LINK
and META tag information. These are given higher
weights than the rest of the text, as we believe that the
information given by these structures is more closely
related to the central theme of the web page.
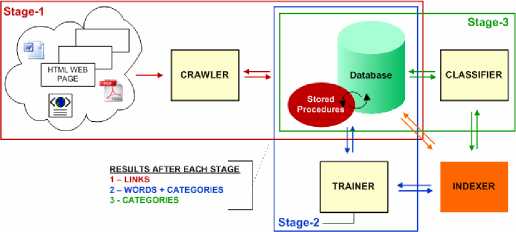
Fig. 1 System Stages
The classification algorithm is then applied to each
category stored in the database. There are only two
categories currently used in this research, relevant and
irrelevant, however, the system is designed to work with
any number of categories. This is to allow for future
growth and potential changes at ATM.
Our classification algorithm is based on the NB approach.
The standard Bayes rule is defined as follows:
fpfr I 'll Р(ИСп) × FCCn)
arg max{P(Cn ∣w)} =----—ʒ----
" ɪ (1)
where:
P(Cn) = the prior probability of category n
w = the new web page to be classified
P(w|Cn) = the conditional probability of the test page,
given category n.
The P(w) can be disregarded, because it has the same
value regardless of the category for which the calculation
is carried out, and as such it will scale the end probabilities
by the exact same amount, thus making no difference to
the overall calculation. Also, the results of this calculation
are going to be used in comparison with each other, rather
than as stand-alone probabilities, thus calculating P(w)
would be unnecessary effort. The Bayes Theorem in (eq.
1) is therefore simplified to:
arg max{P(Cn∣w)} <x P(w∣Cn) × P(Cn)
- ' ' (2)
IJCSI
More intriguing information
1. Cultural Diversity and Human Rights: a propos of a minority educational reform2. Visual Perception of Humanoid Movement
3. Locke's theory of perception
4. The Distribution of Income of Self-employed, Entrepreneurs and Professions as Revealed from Micro Income Tax Statistics in Germany
5. The name is absent
6. Direct observations of the kinetics of migrating T-cells suggest active retention by endothelial cells with continual bidirectional migration
7. Endogenous Heterogeneity in Strategic Models: Symmetry-breaking via Strategic Substitutes and Nonconcavities
8. The name is absent
9. Contribution of Economics to Design of Sustainable Cattle Breeding Programs in Eastern Africa: A Choice Experiment Approach
10. The name is absent