IJCSI International Journal of Computer Science Issues, Vol. 4, No 1, 2009
21
|
______PREDICTED______ | |||
|
IRRELEVANT |
RELEVANT | ||
|
ACTUAL |
IRRELEVANT |
TN / 794 |
FP / 129 |
|
RELEVANT |
FN / 320 |
TP /7482 | |
The vocabulary used in our experiments, consisting of
5217 features, was initially mapped onto a NN with 5217
inputs, one hidden layer with 5217 nodes and 1 output, in
keeping with the standard configuration of a NN, where
the number of midnodes is the same as the number of
inputs. A fully connected network of this size would have
over 27 million connections, with each connection
involving weight parameters to be learnt. Our attempt at
creating such a network resulted in the NN program
failing to allocate the needed memory and crashing.
After paying more attention to the function complexity, we
decided to change the number of midnodes to reflect this
complexity. We, therefore, created a NN with 5217 inputs,
1 output and only 200 midnodes. This worked well and the
resulting NN successfully established all connections.
However, we realised that the NN would need to be
extended (more nodes and midnodes created) to model any
additional, new features, each time they are extracted from
future web pages. This would potentially take the NN
back to the situation where it fails to make all the required
connections and this would be an unacceptable result for
ATM. Technology exists for growing nodes; however, this
would be complex and expensive. Furthermore, the NN
took 200 minutes to train, which is much longer than the
other classifiers, which took seconds for the same training
sample. Therefore, we decided not to proceed with NNs
any further, as they would be unsuitable for our project
and other projects of this kind.
Table 4: Final Results
|
Classifier |
Accuracy |
Precision |
Recall |
F-Measure |
|
NB Classifier |
95.20% |
99.37% |
95.23% |
97.26% |
|
DT |
94.85% |
98.31% |
95.90% |
97.09% |
Table 4 shows the Accuracy, Precision, Recall and F-
Measure results achieved by the NB and DT classifiers,
following the calculations in section 4.1. These results
show that both classifiers achieve impressive results in the
classification of attribute data in the training courses
domain. The DT classifier outperforms the NB classifier in
execution speed and Recall value (by 0.67%). However,
the NB classifier achieves higher Accuracy, Precision and
most importantly, overall F-Measure value, which is a
very promising result.
This result is further confirmed by the comparison of the
two classifiers on the ROC space (Fig.2.), where it is
shown that the result set from the NB classifier falls closer
to the ‘perfect classification’ point than the result set from
the DT classifier.
Table 5: ROC Space Results
Classifier FPR TPR
NB Classifier 0.05092 0.95232
DT Classifier 0.13976 0.95899
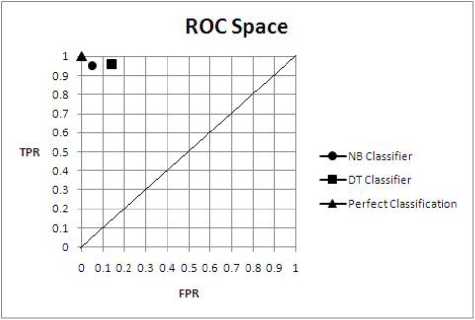
Fig. 2. ROC Space
The ROC space was created using the values in Table 5,
following the calculations in equations (9) and (10).
5. Conclusions
To summarise, we succeeded in building a NB Classifier
that can classify training web pages with 95.20% accuracy
and an F-Measure value of over 97%. The NB approach
was chosen as thorough analysis of many web pages
showed independence amongst the features used. This
approach was also a practical choice, because ATM, like
many small companies, has limited hardware
specifications available at their premises, which needed to
be taken into account.
The NB approach was enhanced, however, to calculate the
believed probability of features in each category. This
additional step was added to handle situations when there
is little evidence about the data, in particular during early
stages of the classification process. Furthermore, the
classification process was enhanced by taking into
consideration not only the content of each web page, but
also various important structures such as the page TITLE,
META data and LINK information. Experiments showed
that our enhancements improved the classifier by over 7%
IJCSI
More intriguing information
1. A Principal Components Approach to Cross-Section Dependence in Panels2. The name is absent
3. National curriculum assessment: how to make it better
4. The name is absent
5. Improvements in medical care and technology and reductions in traffic-related fatalities in Great Britain
6. Cancer-related electronic support groups as navigation-aids: Overcoming geographic barriers
7. Cultural Neuroeconomics of Intertemporal Choice
8. What Lessons for Economic Development Can We Draw from the Champagne Fairs?
9. The name is absent
10. INTERPERSONAL RELATIONS AND GROUP PROCESSES