its view regardless of the caregiver’s attention (see
Figure 1 (a)). At the 12th month, that is the second
stage, the infant begins to track the caregiver’s gaze
and watches the ob ject that the caregiver attends
to (see Figure 1 (b)). However, even at this stage,
the infant exhibits the gaze following only when the
object is within the field of the infant’s view. In
the final stage, the infant at the 18th month is able
to turn around and attend to the ob ject that the
caregiver attends to even if the object is outside the
infant’s first view (see Figure 1 (c)). The develop-
mental phenomena of the infant’s joint attention can
be explained in this way, however, its developmen-
tal mechanism has not been revealed yet. For this
problem, Fasel et al. (2002) presented a developmen-
tal model of joint attention based on a proper inter-
action of innate motivations and contingency learn-
ing. However, the validity of their model has not
been verified through the implementation to an ar-
tificial agent. Nagai et al. (2002) proposed a con-
structive model by which a robot learns joint atten-
tion through interactions with a human caregiver.
They showed that the robot can acquire the ability
of joint attention and the learning becomes more ef-
ficient owing to the developments of the robot’s and
the caregiver’s internal mechanisms. However, their
intention was not to explain the staged developmen-
tal process of the infant’s joint attention.
This paper presents a constructive model which
enables a robot to acquire the ability of joint atten-
tion without a controlled environment nor the exter-
nal task evaluation and to demonstrate the staged
developmental process of the infant’s joint attention.
The proposed model consists of the robot’s embed-
ded mechanisms: visual attention and learning with
self-evaluation. The former is to find and attend to
a salient ob ject in the robot’s view, and the latter
is to evaluate the success of visual attention and
then learn a sensorimotor coordination. Since vi-
sual attention does not always correspond to joint
attention, the robot may have incorrect learning sit-
uations for joint attention as well as correct ones.
However, the robot is expected to statistically lose
the learning data of the incorrect ones as outliers
because the object position that the robot attends
to changes randomly and the data of the incorrect
ones has a weaker correlation between the sensor in-
put and the motor output than that of the correct
ones. As a result, the robot acquires the appropriate
sensorimotor coordination for joint attention in the
correct learning situations. It is expected that the
robot performs the staged developmental process of
the infant’s joint attention by changing the attention
mechanism from the embedded one, that it visual
attention, to the learned one, that is the acquired
sensorimotor coordination.
The rest of the paper is organized as follows. First,
how the proposed model affords the ability of joint
attention based on visual attention and learning with
self-evaluation is explained. Next, we describe the
experiment in which the validity of the proposed
model is verified. Finally, conclusion and future work
are given.
2. The development of joint atten-
tion based on visual attention and
learning with self evaluation
2.1 Basic idea
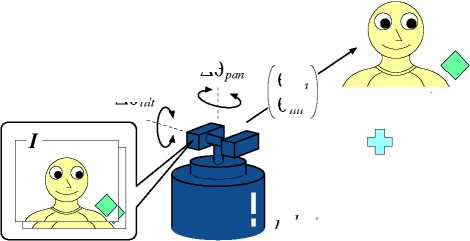
An environmental setup for joint attention is shown
in Figure 2, in which a robot with two cameras, a
human caregiver, and multiple salient objects are in-
dicated. The environment is not controlled, in other
words, the objects are at random positions in each
trial. The caregiver attends to one of the objects
(in Figure 2, it attends to the square object). The
robot receives the camera image I and the angles
of the camera head θ = [θpan, θtilt] as inputs, and
outputs the motor command to the camera head
∆θ = [∆θpan, ∆θtilt] to attend to an object. The
joint attention task in this situation is defined as a
process that the robot outputs the motor command
∆θ based on the sensor inputs I and θ, and conse-
quently attends to the same object that the caregiver
attends to.
θ pan
θ tilt
∆θ
∆θ tilt
robot
Figure 2: An environmental setup for joint attention be-
tween a robot and a human caregiver
caregiver
For the development of joint attention, the robot
has two embedded mechanisms:
(a) visual attention: to find and attend to a salient
ob ject in the robot’s view, and
(b) learning with self-evaluation: to evaluate the suc-
cess of visual attention and then learn a sensori-
motor coordination.
Based on the embedded mechanisms, the robot ac-
quires the ability of joint attention as follows. First,
the robot attends to the caregiver who attends to an
More intriguing information
1. The changing face of Chicago: demographic trends in the 1990s2. The name is absent
3. Wettbewerbs- und Industriepolitik - EU-Integration als Dritter Weg?
4. The name is absent
5. CROSS-COMMODITY PERSPECTIVE ON CONTRACTING: EVIDENCE FROM MISSISSIPPI
6. Tax systems and tax reforms in Europe: Rationale and open issue for more radical reforms
7. Experience, Innovation and Productivity - Empirical Evidence from Italy's Slowdown
8. TINKERING WITH VALUATION ESTIMATES: IS THERE A FUTURE FOR WILLINGNESS TO ACCEPT MEASURES?
9. The name is absent
10. The name is absent