another function to support other standards. Furthermore, we
can define multiple interleavers and switch between them on-
the-fly since the interleaver is defined in software in our GPU
implementation.
E. max * Function
Both natural logarithm and natural exponential are supported
on CUDA. We support full-log-MAP as well as max-log-MAP
[18]. We compute full-log-MAP by:
m*ax(a, b) = max(a, b) + ln(1 + e-|b-a| ) (9)
and max-log-MAP is defined as:
m*ax(a, b) = max(a, b). (10)
Throughput of full-log-MAP will be slower than the throughput
of max-log-MAP. Not only is the number of instructions required
for full-log-MAP greater than the number of instructions required
for max-log-MAP, but also the natural logarithm and natural
exponential instructions take longer to execute on the GPU
compared to common floating operations, e.g. multiply and add.
An alternative is using a lookup table in constant memory.
However, this is even less efficient as multiple threads access
different entries in the lookup table simultaneously and only the
first entry will be a cached read.
V. BER Performance and Throughput Results
We evaluated accuracy of our decoder by comparing it against
a reference standard C Viterbi implementation. To evaluate the
BER performance and throughput of our turbo decoder, we tested
our turbo decoder on a Linux platform with 8GB DDR2 memory
running at 800 MHz and an Intel Core 2 Quad Q6600 running at
2.4Ghz. The GPU used in our experiment is the Nvidia TESLA
C1060 graphic card, which has 240 stream processors running
at 1.3GHz with 4GB of GDDR3 memory running at 1600 MHz.
A. Decoder BER Performance
Since our decoder can change P , which is the number of
sub-blocks to be decoded in parallel, we first look at how the
number of parallel sub-blocks affects the overall decoder BER
performance. In our setup, the host computer first generates
the random bits and encodes the random bits using a 3GPP
LTE turbo encoder. After passing the input symbols through
the channel with AWGN noise, the host generates LLR values
which are fed into the decoding kernel running on GPU. For this
experiment, we tested our decoder with P =32, 64, 96, 128 for
a 3GPP LTE turbo code with N = 6144. In addition, we tested
both full-log-MAP as well as max-log-MAP with the decoder
performing 6 decoding iterations.
Figure 4 shows the bit error rate (BER) performance of the
our decoder using full-log-MAP, while Figure 5 shows the BER
performance of our decoder using max-log-MAP. In both cases,
BER performance of the decoder decreases as we increase P .
The BER performance of the decoder is significantly better
when full-log-MAP is used. Furthermore, we see that even with
parallelism of 96, where each sub-block is only 64 stages long,
the decoder provides BER performance that is within 0.1dB of
the performance of the optimal case (P =1).
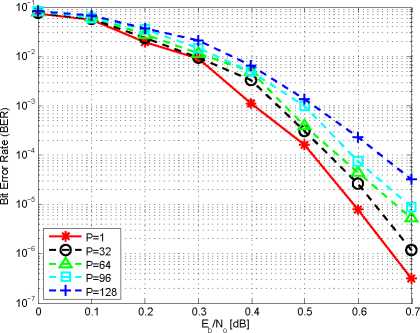
Fig. 4: BER performance (BPSK, full-log-MAP)
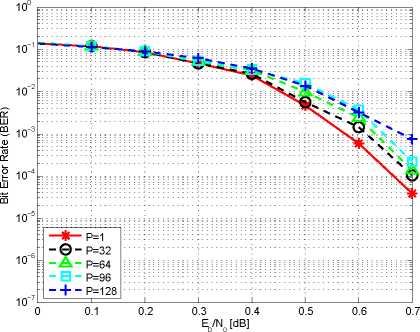
Fig. 5: BER performance (BPSK, max-log-MAP)
B. Decoder Throughput
We measure the time it takes for the decoder to decode a batch
of 100 codewords using event management in the CUDA runtime
API. The runtimes measured include both memory transfers
and kernel execution. Since our decoder can support various
code sizes, we can decode N =64, 1024, 2048, 6144 with
various numbers of decoding iterations and parallelism P . The
throughput of the decoder is only dependent on W = N as
decoding time is linearly dependent on the number of trellis
stages traversed. Therefore, we report the decoder throughput
as a function of W which can be used to find the throughput
of different decoder configurations. For example, if N = 6144,
P =64, and the decoder performs 1 iteration, the throughput of
the decoder is the throughput when W =96. The throughput
of the decoder is summarized in Table III. We see that the
throughput of the decoder is inversely proportional to the number
of iterations performed. The throughput of the decoder after
m iterations can be approximated as T0/m, where T0 is the
throughput of the decoder after 1 iteration.
Although throughput of full-log-MAP is slower than max-log-
MAP as expected, the difference is small while full-log-MAP
196
More intriguing information
1. Quality Enhancement for E-Learning Courses: The Role of Student Feedback2. Who is missing from higher education?
3. Income Growth and Mobility of Rural Households in Kenya: Role of Education and Historical Patterns in Poverty Reduction
4. Innovation Policy and the Economy, Volume 11
5. Migration and employment status during the turbulent nineties in Sweden
6. The name is absent
7. Trade Openness and Volatility
8. INTERACTION EFFECTS OF PROMOTION, RESEARCH, AND PRICE SUPPORT PROGRAMS FOR U.S. COTTON
9. The Veblen-Gerschenkron Effect of FDI in Mezzogiorno and East Germany
10. Howard Gardner : the myth of Multiple Intelligences