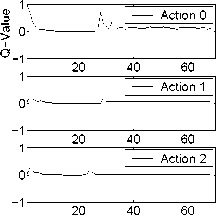
Q-value vs time
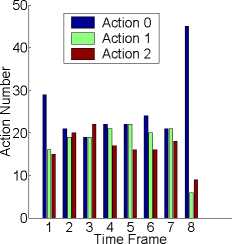
Action Number
Figure 6: Increase novelty witlι a moving object.
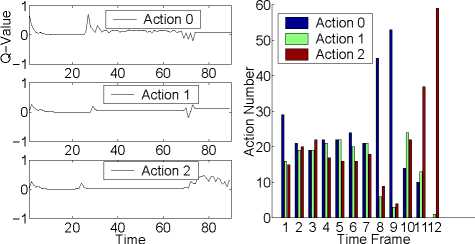
Q-value vs time
Action Number
Figure 7: Suppress novelty with immediate rewards.
5. Experiments with SAIL robot
The next- experiment- is developing value system
of our SAIL robot (short for Self-organizing, Au-
tonomous, Incremental Learner). SAIL shown in
Fig. 8 is a human-size robot custom-made at Michi-
gan State University. It has two “eyes”, which are
controlled by fast- pan-tilt- heads. 28 touch sensors are
installed on its arm, neck, head, and bumper to allow
human to teach how to act- by direct- touch. Its drive-
base enables it- to operate both indoor and outdoor.
A high-end dual-processor dual-bus PC workstation
with 512 MB RAM makes real-time learning possi-
ble. In our real time testing, each step SAIL has 3
action choices: turn its neck left-, turn its neck right
and stay. Totally, there are 7 absolute positions of
its neck. Center is position 0, and from left- to right
is position -3 to 3 Because there are a lot- of noise
in real time testing (people come in and come out),
we restricted the number of states to be less then
50. The dimension of input- image is 30 × 40 × 3 × 2,
where 3 arises from RGB colors and 2 for 2 eyes.
The input- representation consists of visual images
and the absolute position of the robot’s neck. The
two components are normalized so that each has an
equal weight- in the representation. The parameters
are defined as follows: a = 0.9,7 = 0.9 in Eq. 3;
the initial value of θ is 10 in Eq. 4.

Figure 8: SAIL robot at Michigan State University.
5.1 Habituation with positive reward
In order to show the effect- of novelty, we let- the robot-
explore by itself for about- 5 minutes, then kept- mov-
ing a toy on the right- side of the robot-. The absolute
neck position is -2. As shown in Fig. 9, the first-
plot- is the Q-valuc of each action, the second plot- is
the reward of corresponding action, the third plot- is
novelty value and the last- one is the integrated re-
ward. After exploration (200 steps later), a moving
toy increases the novelty of action 0 (stay). At- the
same time, positive rewards are issued to action 0,
so its corresponding Q-valuc (red line) converges to
1 while the Q-vaules of other two actions converge
to 0. The robot- kept- looking at the toy for about- 20
steps. Then we moved the toy to left- side (absolute
neck position is -1), the novelty of action 1 (turn left)
increases (blue line). Finally, at most- time, the robot
would take action 1. However, at step 420, action 0 is
taken again. That is because Boltzmann exploration
is applied. After training, the robot- would prefer to
the Mickey mouse if positive rewards are issued when
staring at the toy (Fig. 10.)
The left- part- of Fig. 11 shows the number of pro-
totypes in each level of the IHDR tree. About- 50
prototypes are generated through incremental learn-
ing. The depth of the tree is 4. The right- part- of
Fig. 11 shows the computing time of each step in
the real time testing. The reason for the changes in
time is that the retrieving time for IHDR tree is not
exactly constant-. For example, if a leaf node keeps
more prototypes, its retrieving time increases. The
average retrieving time is about- 40 ms.
The tree structure is shown in Fig. 12. In the root-
node (q = 5), the first- line shows the 5 prototypes,
the second line shows the disciminating features rep-
resented as images.
More intriguing information
1. The Shepherd Sinfonia2. Spectral density bandwith choice and prewightening in the estimation of heteroskadasticity and autocorrelation consistent covariance matrices in panel data models
3. Proceedings of the Fourth International Workshop on Epigenetic Robotics
4. The name is absent
5. THE UNCERTAIN FUTURE OF THE MEXICAN MARKET FOR U.S. COTTON: IMPACT OF THE ELIMINATION OF TEXTILE AND CLOTHING QUOTAS
6. Modelling Transport in an Interregional General Equilibrium Model with Externalities
7. The name is absent
8. MICROWORLDS BASED ON LINEAR EQUATION SYSTEMS: A NEW APPROACH TO COMPLEX PROBLEM SOLVING AND EXPERIMENTAL RESULTS
9. Demographic Features, Beliefs And Socio-Psychological Impact Of Acne Vulgaris Among Its Sufferers In Two Towns In Nigeria
10. The name is absent