Figure 4: Value of level 1 and level 2 knowledge for G=15
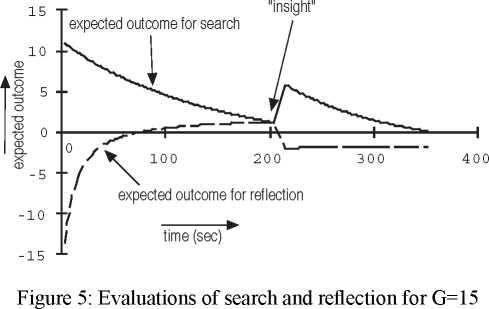
address some of these questions. This model can be seen as a
more detailed version of the dynamic growth model.
An ACT-R model of learning and revising task-
specific knowledge
ACT-R is an architecture of cognition developed by Ander-
son and his colleagues (Anderson, 1993; Lebiere, 1996),
based on the theory of rational analysis. ACT-R has two long
term memory stores, a declarative memory, where knowl-
edge is represented using a frame-like representation, and a
procedural memory, where knowledge is represented by pro-
duction rules. One of the ingredients that ACT-R uses for
conflict resolution is the expected outcome of a production
rule, in the same manner as described in the previous section.
So if several production rules can fire, the rule with the high-
est PG - C will generally win the competition. Along with
the rule the history of successes and failures and the past
costs of a rule are maintained to be able to calculate its
expected outcome.
In the ACT-R architecture, new production rules can be
learned by the analogy mechanism. It involves generalization
of examples in declarative memory whenever a goal turns up
that resembles the example. The examples are stored in spe-
cialized elements in declarative memory, dependency
chunks, that contain all the information needed: an example
goal, an example solution, facts (called constraints) that need
to be retrieved from declarative memory to create the solu-
tion, and sometimes additional subgoals that must be satis-
fied before the solution applies.
Although the ACT-R theory specifies how new production
rules are generated from examples, it does not specify where
the examples come from. But since examples are just ele-
ments in declarative memory, they can be created by produc-
tion rules. If we give a subject a new task, he will generally
have no task-specific rules for the task, but will have to rely
on general rules to acquire them. So the schema to produce
task-specific production rules will be as in figure 6.
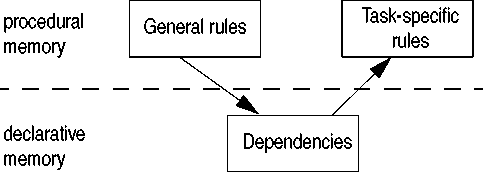
Figure 6: How to learn new production rules in ACT-R
The general rules themselves need of course information
to work with. Several sources of information may be avail-
able, which must be present in declarative memory, since
production rules cannot directly inspect other production
rules. Possible sources of information are:
- Task instructions and examples
- Relevant facts and biases in declarative memory
- Feedback
- Old goals and dependencies for the same problem
As both general and task-specific rules are in a constant com-
petition with each other, they play the same role as the search
and reflection strategies in the dynamic growth model. If
ACT-R uses task-specific rules, this corresponds to a search-
like strategy, and when it uses general rules, this corresponds
to reflection. So there is no real difference in ACT-R perfor-
mance between search and reflection, except that general
rules will often retrieve more low-activated elements from
declarative memory, which makes them slow and expensive.
Since using general rules has a higher cost, task-specific
rules will win the competition if they prove to lead to suc-
cess.
The model
In Taatgen (1996) an example of a model that learns its own
task-specific rules is described. It uses two sets of general
rules, one that creates an example of retrieving a certain
property of the task, and one that creates an example of com-
bining the task with a fact in an attempt to predict the
answer. The example task is a beam with both weights and
labels on each arm (figure 7). Only the weights have any rel-
evance to the outcome. The strategies that do the task are
depicted in figure 8 and figure 9. The property-retrieval strat-
egy creates an example of retrieving one of the available
properties, in the case of the beam weight or label. The
example will be compiled into a production rule by ACT-R’s
analogy mechanism. If the new rule doesn’t lead to success-
ful predictions, which is the case when label is selected, its
evaluation will drop until it loses the competition with the
More intriguing information
1. A Computational Model of Children's Semantic Memory2. The name is absent
3. The name is absent
4. Understanding the (relative) fall and rise of construction wages
5. The name is absent
6. AN IMPROVED 2D OPTICAL FLOW SENSOR FOR MOTION SEGMENTATION
7. Automatic Dream Sentiment Analysis
8. Endogenous Heterogeneity in Strategic Models: Symmetry-breaking via Strategic Substitutes and Nonconcavities
9. The name is absent
10. Growth and Technological Leadership in US Industries: A Spatial Econometric Analysis at the State Level, 1963-1997