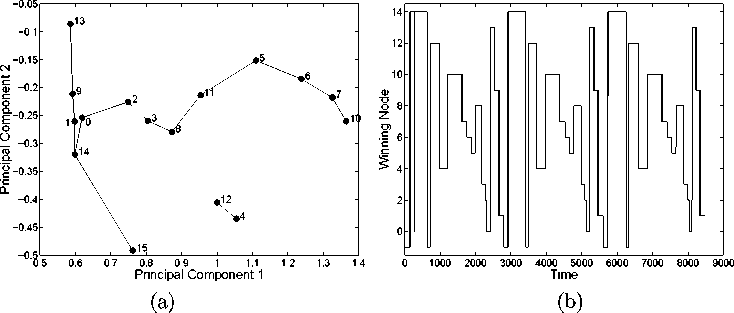
Figure 3: The object-interactions experiment: (a) a SOFM produced by the attention system at the end of a complete
learning episode, projected onto the first 2 principal components; (b) the SOFM node activation at the recall phase.
the demonstrator’s actions. The learning phase con-
sists of 20 demonstration episodes (3000 steps each)
of the object-interaction that was described above.
Figure 3(a) shows one SOFM network that the sys-
tem can produce with particular parameter values.
Since the dimensionality of the input space is quite
high (34 dimensions), we have used a dimensional-
ity reduction technique called Principal Component
Analysis (PCA) to display the SOFM1 (the principal
components used in the figure account for approxi-
mately 80% of the variance).
In Figure 3(a) we can distinguish four parts: one
fairly straight curve (nodes 15-14), a disjoint clus-
ter (12-4-10), two half loops starting at node 7 and
ending at node 0, and another fairly straight curve
(1-13). These parts in fact correspond to the four
parts of the ‘drinking from a glass’ behaviour: (i)
approach the glass; (ii) pick up, bring to the mouth;
(iii) put down; (iv) move away from the glass.
In the recall phase, the structures of the mir-
ror system are fixed; the demonstrator performs the
object-interaction again, but now the imitator tries
to match this behaviour; the interaction is repeated
3 times (again 3000 steps each). The SOFM re-
ceives continuous perceptual input which activates
the best-matching node; the corresponding motor
schema provides a motor target, which is simply the
SOFM node vector; the target is passed to the motor
system where motor commands are calculated by the
inverse model, to achieve the perceptual state recog-
nised by the SOFM node. If the winning node does
not match the input well enough (signalled through
the novelty threshold), then no motor commands are
produced and the imitator maintains its current pos-
ture; this illustrates recognition failure either due
to unfamiliar visual perception, insufficient learning,
or inability to learn what was demonstrated in the
1PCA finds the most statistically significant dimensions,
called Principal Components, in a multivariate dataset.
learning phase.
Figure 3(b) shows the SOFM activation during the
recall phase, i.e. the sequence of nodes that are acti-
vated in response to the input, for the SOFM shown
in Figure 3(a). A winning node of —1 indicates a
poor match and hence no winning node. We observe
that the SOFM nodes created at the learning phase,
are activated in sequence at the recall phase; node
14 represents grasping the glass; nodes 12-4-10 rep-
resent lifting the glass and moving it to the mouth;
nodes 7-6-5-8-3-2-0 from the mouth back on to the
surface; node 13 away from the glass (towards the
starting posture); nodes 9-1 towards the glass once
again.
4-2 Results
Figure 4 shows the trajectories of the right-hand
wrists of both the demonstrator (in bold font) and
the imitator (normal font) in a single episode in the
recall phase. Figure 4(a) shows a successfully learned
action, i.e. the trajectories are close to each other,
whereas Figure 4(b) shows a less successful one: the
trajectories are further apart. This reflects exactly
what we have visually observed: natural motor con-
trol with reasonable degree of accuracy imitation in
Figure 4(a), and much less accurate in Figure 4(b);
in the latter the imitator misses its mouth and does
not place the glass back on the table.
As well as visual inspections, we are also evaluat-
ing our system numerically on a task-specific basis.
In this experiment we use two evaluation measures:
a ‘distance’ measure, which calculates the position
of the wrist over time relative to the position of the
demonstrator’s wrist (i.e. the distance between the
two curves in the plots of Figure 4), and a ‘score’ for
successful execution of the task (i.e. picking glass
up, drinking, putting down). The measures are de-
scribed in more detail below.
The analysis of the results consists of evaluating
More intriguing information
1. Ventas callejeras y espacio público: efectos sobre el comercio de Bogotá2. Tourism in Rural Areas and Regional Development Planning
3. The name is absent
4. ROBUST CLASSIFICATION WITH CONTEXT-SENSITIVE FEATURES
5. Plasmid-Encoded Multidrug Resistance of Salmonella typhi and some Enteric Bacteria in and around Kolkata, India: A Preliminary Study
6. Inflation and Inflation Uncertainty in the Euro Area
7. The name is absent
8. Job quality and labour market performance
9. Transport system as an element of sustainable economic growth in the tourist region
10. Voluntary Teaming and Effort